



At the end of June, the Homebrew Website Club meeting #10 took place at Potsdamer Platz Starbucks. Somehow it was our pragmatic solution for our location problem. We were again a great mix of 6 people with a diverse skill set. I am always suprised about the wide range of interdisciplinary knowledge our HWC Berlin member have. It goes from Social Science, to User Experience, Interaction Design, to Web Development, to strong Computer Science knowledge on all areas. Even better, everyone is very open to share their knowledge with the others. After a series of events, we achieved a good vibe from my point of view.
Back to the core topic of our meeting No. 10, which was completely dedicated to the IndieWeb barebone infrastructure “Webmentions“.
Webmentions in general
Webmentions provide a feedback channel for referencs and quotations. It works pretty similar to Pingback, but with some improvements. During our discussions, we came to the point to make that clear statement
Webmentions just do a “ping” to another website
It behaves like a “hello” greeting signal. What the receiver of this signal does and how s/he response to it, depends completely on the interpretation of the receiver. There doesn’t exist a fix rule set. Of course, the IndieWeb provide some recommendations, but if you want to implement your own ideas, than you are free to do. During our discussion we came to the result:
Webmentions mostly provide the barebone infrastructure of Activity Streams
It behaves more or less like the Facebook or Twitter stream. Such a stream of data is mostly a (linear, chronical) collection of online activities (postings, quotes, retweets, likes and so on). Such content is usually visualized on the owner of an IndieWeb website and builts a basic infrastructure of the Indie Web community. In contrast, the standard ActivityPub by W3C adresses similar issues. Activity Streams define more or less the format of the data. This could be partly solve with webmentions, too. The standard around ActivityPub by W3C dealts with the transportation of the data. Thanks @Sven for your feedback!
Good visualized content can only be reached with the help of good semantic data. Therefore, the sender and also the receiver web page is supposed tp provide valid semantic content (in HTML, Microformats, JSON-LD, etc.), though the receiver can “crawl” and “make sense” of the content. More about crawling later.
If you want to implement your own webmentions, please consider that webmentions are an offical W3C standard. It exists a “recommended” rule set, how a webmentions endpoint must be designed. Here are some further resources:
- https://webmention.io/
- https://www.w3.org/TR/webmention/
- https://indieweb.org/Webmention-developer
- https://webmention.rocks/ (Testsuite)
Design and technical requirements
Honestly, a good documentation about requirements and implementation is available on the IndieWeb Wiki. There is almost nothing to add. Nevertheless, I would like to describe my personal point of view. In the most cases, I try to get sense out of a system by analyzing its interactions. Therefore, I will describe the webmentions from my very subjective point of view. In my world of thinking, websites or web apps should be encapsulated in frontend and backend logic. This can also applied for the sender and receiver of webmentions. The diagram shows how such a webmention signal could flow through the different infrastructures of the two websites (full resolution). The “update” and “delete” action by webmentions is not considered the diagram.

Frontend for the sender of webmentions / User Input channel for webmentions:
First, if you sent a webmention to someone, please be sure that you provide a semantic content structure. If you do it already, then you are cool person! 😉 Next step, as far as I know there are two strategies of sending webmentions to another website. The sender can do it manually or automatically in the background.
For instance, if the sender (me) writes a blog post, then the sender’s editor (e.g. Gutenberg by WordPress) could send automatically webmention to each outgoing link within your written content. That means no real change for the editor’s UX. The content producer just creates a-href links as s/he is used to. The editor creates a list of “sending webmentions” commands in the background and transmitts them to the sender’s backend. The sender’s backend deals with the commands hopefully in an asynchronous style.
The manual approach requrires direct interaction by the user. That means the editing software could offer a special button or an UI for sending webmentions. It has another positive side effect, that no direct link within your content is needed. A very good use case for this is indirect citations. Another very common approach by some Indie Web website is a special input interface below the content of the “receiver” website to send a webmention. Matthias Ott and Drew McLellan provide a very nice implementation of this direct user interaction of webmentions:
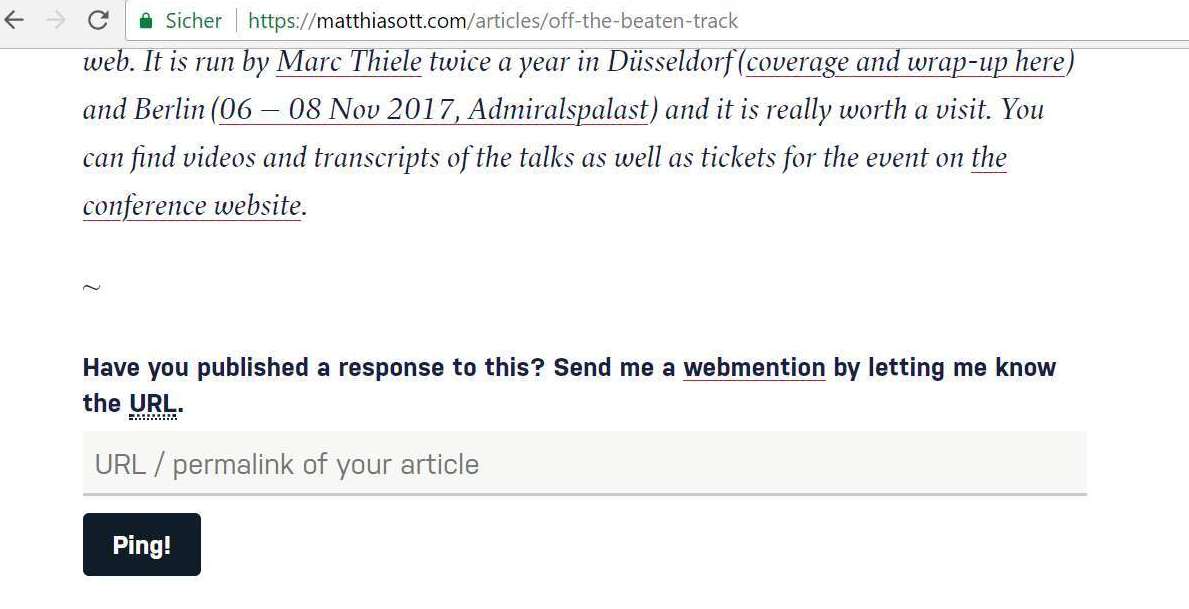
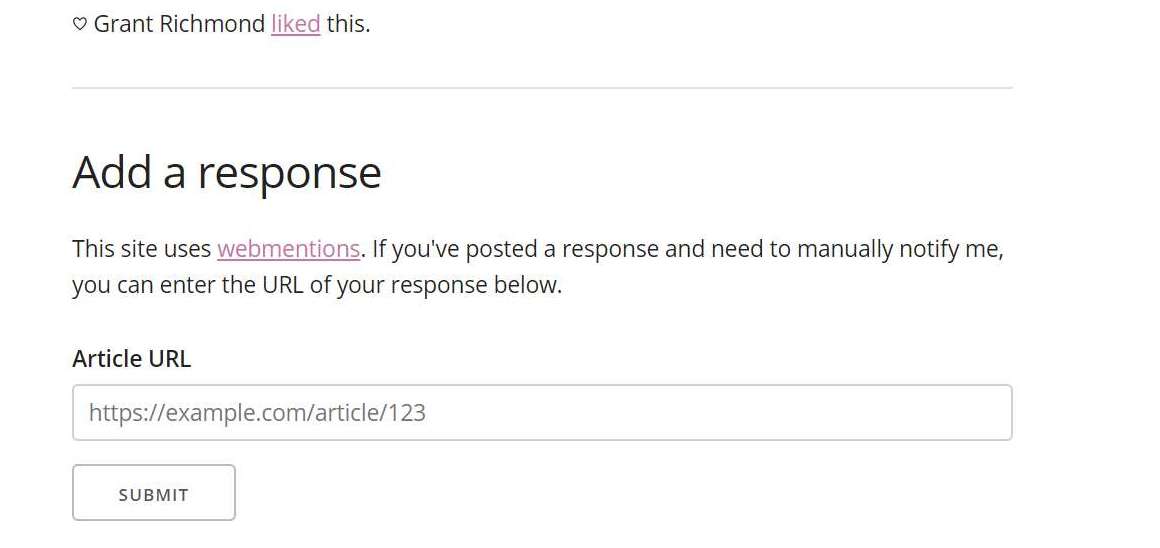
If none of these suggestion meet your needs, you are completly free to create your own user interface solutions. Please share your idea with the IndieWeb community. They are always open for new ideas.
Backend of the webmention sender:
If you just have a link stored at your backend, then your backend logic has to check if webmention API endpoint is available at the receiver side.
- Such discovery of the receiver’s webmention endpoint happens usually while fetching the HTML Meta Tags for the target (website) source.
- If webmention API endpoint on the receiver side exits, then send a webmention via HTTP Post request with the correct HTTP Headers and the correct data body.
- Please consider: If you want to send a bundle of webmentions, please send them asynchronously to the target URLs. Otherwise, there exist the danger of using webmentions as a vector of DoS attacks. Check Cron Jobs, or other worker and job queue implemantions as helper for this use case.
- You should get a positive response, like a HTTP 2xx back
That’s it mostly about the basic principles on the sender side. The IndieWeb community established some additional implemenations, which you should be aware of:
- Private webmentions for taking care of your user’s privacy. That includes adding token and authentication management to your webmention API endpoint.
- Locate and assign special content parts via Fragmention and Media Fragments. Add some more data to our urls, as described in the Media Fragements W3C Recommendation.
The website “webmentions.rocks” is great resource for running your code against some common testcases. For more detailed information please check the specifications.
Backend of the webmention receiver:
It is obvious that your website needs a Webmention API endpoint.
- Provide a webmention API endpoint on your site
- Receiving a Webmention signal
- Then validate the request and check if you trust the webmention signal
- If you trust the initial request, then send a HTTP 2xx response back to the sender
Until here the basic stuff is done. You got successfully notified that someone made a successful reference to you. In some cases it makes sense to make a visual feedback for your content. For instance, in science publications the number of references is one(!) indicator of a few quality measurements. Therefore, as writer have an interest to show who and what kind of content linked to you. Before such webmention references could be visualized on the receiver website, the backend has to fetch/crawl the content. In that context, the receiver also needs a job timeline for gather the sender’s content. It works similiar to the Social Media share a link mechanism
- Use the “source url” of the senders webmention signal, which you trust. If you don’t trust the url, then don’t fetch the content
- Fetch the content from the website asynchronously. Otherwise, webmentions could be used as a vector of DoS attacks. (Check Cron Jobs, or other worker and job queue implemantions as helper for this use case. )
- If you got the pure content, please parse it with a Microformat Parser, JSON-LD or other approaches.
- Make sense of the content, that means figuring out if the content is an article, photo, video, event or an user interaction (likes, shares and retweets).
- Prepare and store the content structure for the frontend
That are the basic principles on the backend of the webmention receiver. The tool “webmention-testpinger” can help you to make your Webmention API more stable. For detail information please check the specifications.
Frontend of the webmention receiver:
The frontend of the receiver can be very simple. It must only inform the sender if the website supports webmentions. If yes, then the frontend has to guide the sender’s backend to the receiver’s webmention API endpoint. The second step of showing off webmentions on the receiver site is optional. We guess that we implement both steps:
- Provide a webmention service discovery to the webmention sender
- Add a meta tag to your HTML Header area with the location of the webmention API Endpoint (see code snippet below)
|
1 2 3 4 5 |
<html> <head> <link href="http://aaronpk.example/webmention-endpoint" rel="webmention" /> </head> </html> |
Optional Content crawling and webmention feedback rendering
The backend of the receiver should have already prepared the webmention feedback data for the frontend. There is a few things the frontend must do
- Provide a rich collection of visual templates for the appropiate content
- Check if the webmention is a private one or supports some other features (e.g. Fragmention data)
- Please respect private webmention and its call for privacy.
- Please anonymize private webmention or just don’t show them to the public
- Fragmention are very good to show the most meaningful content part
- Add the webmention on appropiate location, which is a classical web design (and layout) challenge
- Show a reference to the linked content.
A few paragraphs later, I will list some more findings of our meetup about private webmentions. Until now, here are some nice visual examples of webmentions on the receiver side. These two examples are from Matthias Ott and Sebastian Greger. Further cool examples are available on the IndieWeb Wiki.
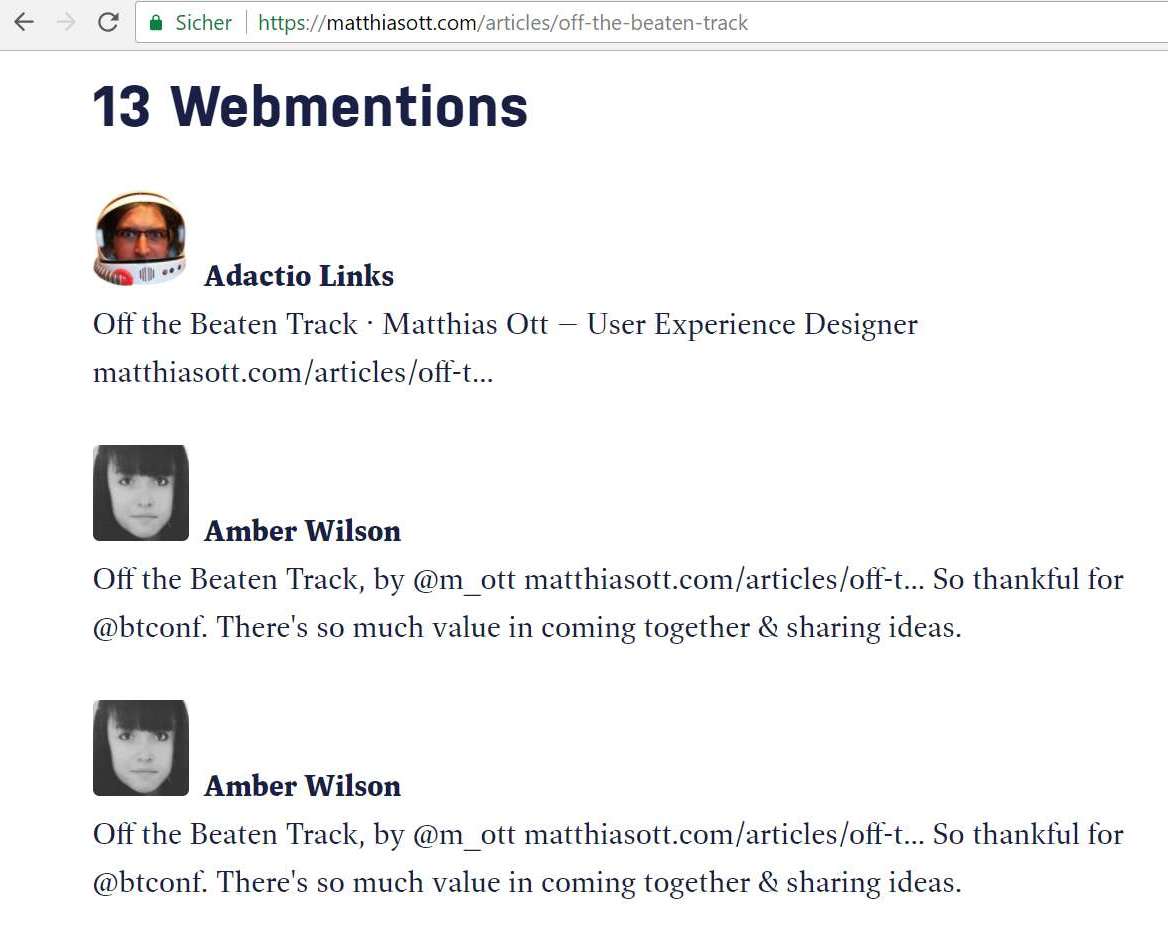

Permalinks: long-term living webmentions
Webmentions is all about creating connections between web content. Those connections are established with URLs/URIs. Unfortunately, the last 20 years have shown that URL links can disappear very fast. The initiative around IPFS tries to solve that problem, but at the moment a transition won’t happen in a near future. Until then, we have to focus on our available technology. We came up in our meetup and on some meetups before, that it is possiple to prepare for the “link rot” phenomen. Just take some time and create your appropiate permalink concept. WordPress provides such a feature already for years. Within our group discussion we came up, that the “creation date” and the “content category” has an important meaning. If you now at least one of these, you can even find the content again when it is moved to another location. I like this strucute Permalink structure very much
|
1 |
https://www.yourdomain.example/category/year/month/day/title_of_your_content |
If the “content category” doesn’t exist anymore, then you can still give ‘time-based’ output. That should enable content seperation and content collection by time. The URL Rewriting rules for this concept should not be so complicated (for Apache, nginx, and caddy). More information about permalinks again on the IndieWeb Wiki.
Logial and semantic structure of your web content
If your website content connects to another web content, then you as a human has a easy game to make sense out of it. Computer algorithms aren’t very advanced in making semantical sense of information (yeah, I know the community of Convolutional neural networks and t-SNE working on solutions for audio and visual object recognition). This whole semantic topic was around 10-15 years very hot under the term Semantic Web. It never really left the academic world, due to a really worse developer UX (RDF and OWL editors just sucked. However, nowadays we have some other much more developer friendly solutions. In that context, I am not talking about the Social Media platform solutions provided by Facebook, Twitter, and LinkedIn, because the differ from each other. That sucks! We are talking here about offical open standards, like Microformats and JSON-LD, which provide a sustainable value (e. g. in terms of Humane Tech).
Since our first meeting, we have strong discussion about Microformats and JSON-LD as a semantical desciption layer. The IndieWeb community are strongly committed to Microformats. Personally, I don’t like how Microformats are applied in my HTML and CSS structure. I think our discussions was kinda all the time about Content and Display Patterns. After hours of discussions, we found very good consense during our Webmention meeting.
We can live with both and should support all of them – Go for Microformats and JSON-LD!!
Microformats are very good to assign a semantic value directly within your content markup. The advantage of this “display pattern” solution is the direct manipulations(!) of content pieces. That could provide better content edit and exchange UX for all end user. Content Data about Events, Places, Photos and so on could be easily transferred between different software apps. Another use case is a special rendering. Content pieces could be visualized differently by web extensions. For instance, accessibility applications could use this additional information. I am pretty sure there exist more use cases.
JSON-LD is very good to provide meta-data of a website in a machine readable format. You should support JSON-LD, because it is easier for a Webcrawler (e.g. Crawlbot by diffbot) to make sense out of your content (check this article). The information overhead is much less compared to microformats, because it meets directly the needs of the content pattern approach. Moreover, you have the possibility to emphasize the most important parts of your content. Schema.org provides a huge collection of content descriptors. Check this out before you implement a new web app.
** Update 2017.12.09: I got some feedback that not all JSON-LD Schemas from schema.org are applied in production mode. It is still in experimenting period, therefore please provide and share your experiences with schema.org formats. ***
Furthermore, the search index of Google applies such JSON-LD schemas, which can have an significant influence on your SEO.
In my opinion, JSON-LD is more appropiate for fetching the content dispatched by webmentions. Webmentions are mostly interested on your content patterns and not on your display patterns. In terms of “Webmention Fragmentions”, this statement doesn’t work anymore. Both solutions within your website cause redundant data, which can cause inconcurrent data. However, this all is highly technical and depends on your CMS and implementations. During our webmention meeting, we agreed to keep the data overhead as minimal as possible. We suggested to apply the same discovery mechanism as it is used for webmention for machine readable content.
Add discovery endpoint for your machine-readable content provider within your HTML
Such approach has the advantage, that the semantical structure can be technology independent. It even could be a workaround for Single-Page-Apps. The webmention receiver can discover directly the preapared machine-readable content, which is very appropiate from a machine2machine communication view. The HTML Head area is your best friend in that case. A few inspiration what does it mean in pragmatic terms:
For JSON based systems
|
1 2 3 4 5 |
<html> <head> <link href="https://mydomain.example/provider/json/content_id" rel="meta_json" /> </head> </html> |
JSON is nowadays very common data format for REST APIs. Luckily, most CMS support this format. For instance, in WordPress it doesn’t sound complicated to provide an endpoint. You should somehow provide a JSON endpoint to your site.
For oEmbed based systems
|
1 2 3 4 5 |
<html> <head> <link href="https://mydomain.example/provider/oembed/content_id" rel="meta_oembed" /> </head> </html> |
Another pretty common format for describing media content is oEmbed. It has a pretty clear and and consistent structure. It is widely supported by Facebook, Vimeo, YouTube, WordPress (Editor | Plugin), and so on.
For XML based systems, like RSS and Atom
|
1 2 3 4 5 6 7 8 |
<html> <head> <link href="https://mydomain.example/provider/rss/content_stream" rel="alternate" type="application/rss+xml" title="RSS Feed for content category XYZ of mydomain.example" /> <link href="https://mydomain.example/provider/atom/content_stream" rel="alternate" type="application/atom+xml" title="Atom Feed for content category XYZ of mydomain.example" /> </head> </html> |
RSS and Atom (alternatively JSON Feed) are classical and very appropiate for summarize a collection of content items. In that term is perfect for content streams. Many software tools exists to parse, read, and notify users about new new publications. They could be also very interesting from an event-driven service architecture point of view. In that context, David Yates and David Nield summarize very well the big advantages of RSS and ATOM in contrast to Facebook & Twitter. We all agreed, don’t underestimate the power of free & open standards.
Final thoughts on semantic structures
An appropiate semantical representation of your content isn’t easy. Even the time of rendering plays an important role. Single Page Applications and its tool chain with React, AngularJS, and VueJS can break fetching your content. Server–Side–Rendering of these tools can help you to avoid broken semantic content, even more it makes the content easier crawable. Therefore, please check out that your semantic content is always curlable! Hopefully, this short overview explained some of the differences. In my opinion, there does not exist any right or wrong. Just go for the tool, which meets your needs!!
During our discussion, we figured out one critical point. The “discovery” process of your content is not 100% well defined. At the moment, there exist different kind of implementations, which are not completely compatible with each other. Another location for discovery service for your content items could be the sitemap.xml. During our meetup we could not find a perfect solution.
At the next IndieWeb Camps, it would be nice to talk about these discovery endpoints for content providers. A similar community agreement, like it happen wit the webmention API endpoint, could solve that problem. I am looking forward!
References
Standards
- Webmention – W3C Recommendation
- Indie Web – Wiki – Webmentions
- Wikipedia – Activity Streams
- ActivityPub – W3C Candidate Recommendation
- Activity Pub. rocks
- Indie Web – Wiki – Permalinks
- Media Fragments URI 1.0 – W3C Recommendation
- Indie Web – Wiki – Fragmention
- Microformats (2)
- JSON-LD on Schema.org
- oEmbed Spec
- RSS Feed
- JSON Feed
- Sitemaps.xml
- A free guide to <head> elements
Artikel
- Implementing Webmentions by Drew McLellan
- JSON-LD rewrites the Semantic Web
- Content and Display Patterns (on medium) by Dan Mall
- Content and Display Patterns revisited Brad Frost
- Single Page Web Apps and SEO
- If it’s not curlable, it’s not on the web
- The Average Lifespan of a Webpage
- The growing problem of Internet “link rot” and best practices for media and online publishers
- URL as UI by Jakob Nielsen
- URLs are UI revisited by Scott Hanselman
- Cool URIs don’t change
- How to add RSS Autodiscovery to your site
- RSS: there’s nothing better
- Why RSS Still Beats Facebook and Twitter for Tracking News
- What do you mean by “Event-Driven”?
- Humane Tech





3 Comments
Chris Aldrich wrote some nice articles what kind of applications you can achieve with the help of webmentions:
http://boffosocko.com/about/website-philosophy-structure/
http://boffosocko.com/2017/12/15/threaded-replies-with-webmentions-in-wordpress/
http://boffosocko.com/2017/12/24/adding-simple-twitter-response-buttons-to-wordpress-posts/
It would be interesting to see how such applications and features behave to the indie web:
https://pfrazee.github.io/blog/achieving-scale
https://hashbase.io/about
Further new article about webmentions and other related API stuff
https://aaronparecki.com/2018/06/30/11/your-first-webmention
https://alistapart.com/article/webmentions-enabling-better-communication-on-the-internet
https://aaronparecki.com/2018/07/07/7/oauth-for-the-open-web